Why do scientists tend to prefer PDF documents over HTML when reading scientific journals?
16 August 2012
I’m taking a play out of Bradley Voytek’s playbook and re-posting one of my answers to a question on Quora…
Why do scientists tend to prefer PDF documents over HTML when reading scientific journals?
For me, there is one primary reason that I prefer the PDF versions of scientific documents:
**
PDFs have less clutter**
They certainly don’t have to, but since publishers apply the standards of print design to the design of their publications, there is more efficiency in the PDF format.
For example, here are the HTML and PDF versions of the topmost portion of a recent Nature paper… this is essentially what I see in my browser.
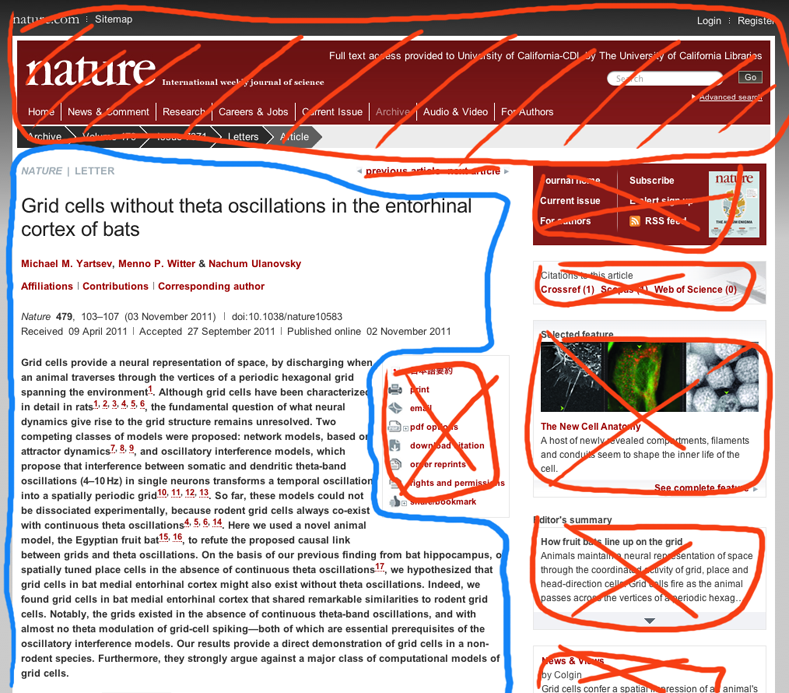
Circled in blue are the things that I am looking for… This is the actual content of the article in question. In red is all the stuff I don’t care about.
That a lot of red, mostly for either advertisements or other services by the publisher.
Now for the PDF of the same paper…

The only thing in red here is the DOI. This is actually important, but I don’t usually need to read it and I felt bad failing to put any red on the PDF. And the figure shows up on the first page, which means that a quick glance gives me some information about the topic of the paper.
But seriously, look at that difference. In the PDF, nearly the whole space is dedicated to content and what’s not content is well formatted whitespace. In the HTML, I have to actively ignore the advertisements, not to mention the bright red hyperlinks to references in the main text.
What can publishers do?
Format HTML documents for readability and stop trying to distract me into reading something else.
**
**I have to read lots of papers and I need to be able to easily find the things that I’m looking for. Second guessing whether I am reading journal content or an advertisement or navigation doesn’t help at all. Reading the HTML version is like trying to read a fitness magazine, where ads and content blur into one incomprehensible mess.
(A second, less important reason is that PDFs feel more stationary. I have more certainty that a PDF I download today is the same as the one my colleague downloaded last week. I know that PDFs can be generated on the fly, but this is how it “feels”.)